HG官网(HoGaming) 山大、理思汽车和中科院接洽提议新范式: 让Transformer去其糟粕


离线强化学习(Offline RL)的一浩劫点是:考验数据固定、质料庞大不皆。近两年,Decision Transformer(DT)等基于 Transformer 的圭臬因为把有野心建模成要求序列生成而受到热心,但它们往往把「整条轨迹」行为学习单元:要是一条轨迹的最终酬谢不高,轨迹中间即便出现过有用动作与局部生效,也容易被合座低酬谢「稀释」。
针对这一痛点,山东大学、中科院、理思汽车与清华大学的盘考团队接洽提议了一种名为 PRGS(Peak-Return Greedy Slicing)的新框架。
PRGS 的目的是在不改换离线数据来源的前提下,从原始轨迹中自动筛选出更有学习价值的子轨迹(sub-trajectories),用于考验 Transformer 型离线 RL 圭臬,并在推理阶段进一步幸免「倒霉历史」对现时有野心的喧阗。
在 D4RL、BabyAI 等主流榜单上,PRGS 不仅越过各式基线圭臬,更让 Transformer 类圭臬的平均性能擢升了 15.8%!
本论文的第一作家徐志伟,山东大学通用智能实验室助理教练。于 2024 年在中国科学院自动化盘考所获博士学位,盘考内容主要为强化学习、多智能体系统与基于大谈话模子的 AI Agent。曾获取 2025 年度中国智能体与多智能体系统优秀博士论文提名等荣誉。
目下,该论文已汲取于外洋狡计机顶级会议 ICLR 2026。ICLR(International Conference on Learning Representations)是机器学习与示意学习领域的外洋顶级会议之一,与 NeurIPS、ICML 比肩为东说念主工智能倡导最具影响力的学术会议。本次 ICLR 2026 共有接近 19000 篇有用投稿,汲取率约为 28%。

论文标题:Peak-Return Greedy Slicing: Subtrajectory Selection for Transformer-Based Offline RL
01 痛点:按「整条轨迹」学习,粒度不够细
在离线 RL 中,数据是固定的,不成像在线 RL 那样去欺压试错。现存的 Transformer-based 圭臬(如 DT),本色上是在作念要求序列建模。它们频频以「最终酬谢(Final Return)」为要求来生成动作。
这带来的问题是无庸赘述的:
粒度偏粗: 模子只可看到一条轨迹的合座报覆信号,难以诀别轨迹里面不同时间段的质料互异。
九游体育NINEGAMESPORTS缝合智商缺失: 由于短少局部优化目的,模子很难从多个平时计谋中提真金不怕火出最优片断并组合成新的齐全计谋。
诚然也有盘考试图通过重采样或加权来缓解,但大多治标不治本,莫得长远到时候步(Timestep)级别去圣洁化操作。而 PRGS 的出现,恰是为了龙套这一僵局。
02 中枢解法:从全局建模到圣洁化切片
PRGS(Peak-Return Greedy Slicing)不错知道为一个面向 Transformer 离线 RL 的数据处分与推理增强框架,包含三部分:酬谢意想、无餍切片、推理时自合适截断。
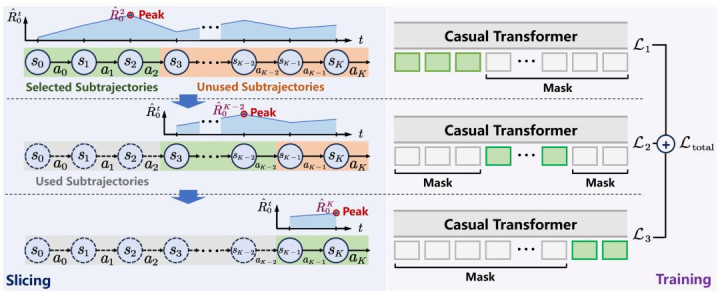
它的中枢逻辑特别像东说念主类的学习经过:回归昔日的阅历,哪怕结局是失败的,也要找出其中作念得最佳的那一段,刻在脑子里。
PRGS 包含三个丝丝入扣的模块:
第一步:MMD-based Return Estimator:用散播视角作念更「乐不雅」的酬谢意想
PRGS 领先需要答复:在轨迹里面,哪些时候段更可能带来高酬谢?为此作家引入基于最大均值互异(MMD)的酬谢意想器,用来描摹情状-动作对的潜在酬谢散播。
不同于传统的均值预测,MMD 意想器能预测情状-动作对的潜在酬谢散播。通过对散播采样并取 Top-n 均值,PRGS 获取了一个乐不雅的酬谢意想值。浮浅来说便是:它能挖掘出现时情状下可能达到的最佳收尾,HG官网(HoGaming)而不是平均收尾。
第二步:Greedy Subtrajectory Slicing:围绕峰值酬谢作念递归切片
在得到每个时候步的「乐不雅酬谢」后,PRGS 对单条轨迹奉行无餍切片:PRGS 会扫描整条轨迹,狡计每个时候步的「乐不雅酬谢」。然后,它会找到阿谁酬谢最高的点——峰值点(Peak Point)。
切。 以这个峰值点为界,从源流到峰值点的这一段,被认定为「高质料子轨迹」,径直拿去考验 Transformer。
再切。 剩下的部分,再重新找峰值,赓续切,直到切完为止。
这种递归式的无餍计谋,把长轨迹拆成一组更短、质料更聚焦的子轨迹,从而让 Transformer 在考验中更经常地搏斗到「相对高酬谢」的有野心片断。
第三步:Adaptive History Truncation:推理阶段的自合适截断
PRGS 还磋议了一个实践问题:模子考验时看到的是「从轨迹中段截取出来的子轨迹」,推理时要是历久把通盘历史高下文都喂给模子,早期的低质料动作可能会喧阗后续有野心。
PRGS 引入了一种自合适历史截断机制(AHT):每走一步,模子都会评估现时情状的价值。要是发现当今的处境比历史纪录清晰的更有出路,讲明之前的历史仍是不仅没用,反而成了牵扯。这时候,模子会审定失忆,丢掉历史高下文,如释重担。
03 实验:多场景达到 SOTA弘扬,复杂场景更强
盘考团队在 D4RL(联络甘休)、BabyAI(当然谈话辅导随从)以及 AuctionNet(大领域告白竞价)三个迥乎不同的基准上进行了测试。
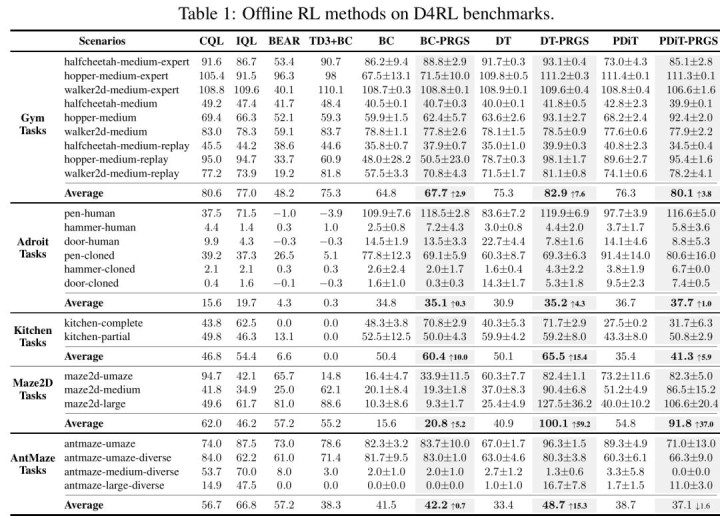
D4RL 场景中弘扬惊艳
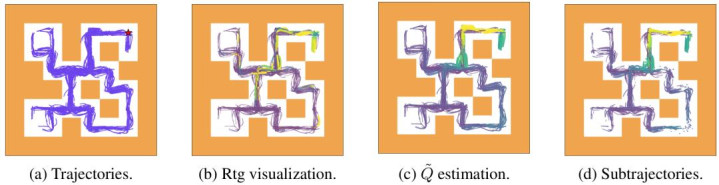
在经典的 MuJoCo 和 AntMaze 任务中,PRGS 的弘扬号称惊艳。非常是在需要极强「缝合智商」的 Maze2D-Large 迷宫任务中,DT-PRGS 的得分高达 127.5,而原始 DT 只消不到 30 分。
在迷宫任务中的可视化收尾也清晰,通过 PRGS 提真金不怕火出的子轨迹,精确地障翳了通往目的的「黄金旅途」,险些剔除了通盘绕弯路的无效探索。
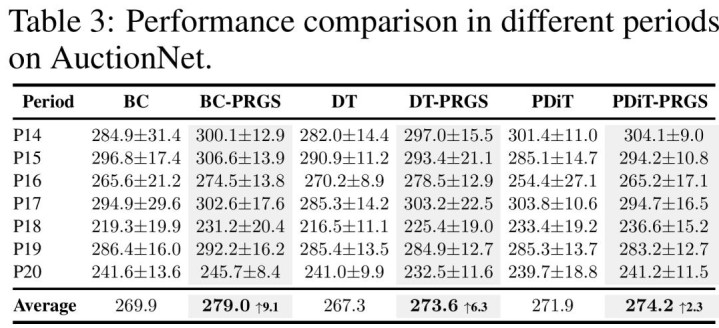
的确业务场景的后劲
除了学术榜单,PRGS 在 AuctionNet(阿里姆妈开源的告白竞价数据集)上也弘扬出色。比较于 BC(行为克隆),加握了 PRGS 后的 BC 算法在多个周期内齐备了权贵的利润擢升。
04 总结与磋议
PRGS 的生效讲明注解了一件事:在离线强化学习中,数据不仅要「多」,更要「精」。
通过 MMD 意想器、无餍切片和自合适截断这套组合拳HG官网(HoGaming),PRGS 生效地让 Transformer 具备了「取其精华,去其糟粕」的智商。这一后果也为自动驾驶、机器东说念主甘休等工业级欺诈提供了极具价值的技巧参考。
 备案号:
备案号: