HoGaming 无用任何东说念主类谈话隆重, 大模子反而更强了?


机器之机杼剪部
若是有一天,大模子不再依赖东说念主类谈话隆重,会发生什么?
畴昔几年,大模子才调的飞跃实在都斥地在一个前提之上:海量文本数据。互联网、竹素、代码、论文,实在所有东说念主类留住的谈话足迹,都被算作隆重数据。但跟着高质料文本渐渐面对勤勉,计划者来源提议一个更激进的问题:
谈话,果真必须是智能的来源吗?
澳门新浦京游戏下载官网最新的一项计划给出了一个令东说念主不测的谜底:也许不需要。他们假定让谈话模子在学习谈话之前,先在统统非谈话的合成数据上进行隆重。
论文使用了一种统统不同的数据来源:在神经细胞自动机(Neural Cellular Automata, NCA)生成的数据上对 Transformer 进行预预隆重(pre-pre-training)—— 这些数据统统是合成的,不包含任何谈话内容。
落幕骄贵,这种法子能够将谈话建模性能升迁最多 6%,将隆重拘谨速率加速 40%,并增强模子鄙人游任务中的推理才调。
这种款式的遵守致使越过了在当然文本上进行预预隆重(pre-pre-training)的模子。


论文标题:Training Language Models via Neural Cellular Automata
博客:https://hanseungwook.github.io/blog/nca-pre-pre-training/
当然谈话,果真是通向智能的独一起路吗?
本文的中枢假定是:谈话之是以适当用于预隆重,要道并不在于它的语义,而在于它所具备的结构。若是这小数配置,那么那些通常具有丰富结构、但并非谈话神气的数据,表面上也可能被用来隆重智能系统。
在得出这一假定之后,本文提议诓骗 NCA 生成合成的、非谈话数据,用于对大谈话模子进行预预隆重(pre-pre-training),即先在合成数据上隆重,再在当然谈话上不竭隆重。
值得一提的是,预预隆重是本文提议的一种隆重范式,模子先学习 NCA 序列,然后再在语料库上预隆重,临了微调。

NCA 数据具有丰富的时空结构,其统计特点在某些方面与当然谈话相似,同期又可控且易于大范围低本钱生成。
另外,NCA 是对康威人命游戏(Conway’s Game of Life)(Gardner,1970)等系统的一种实行:它通过用神经网络替代固定的能源学规定,来界说系统的演化经由,并能够在空间局部规定的基础上生成各样化的数据漫衍。
这种机制能够产生大肆范围的长程时空模式(见图 1),并呈现出重尾(heavy-tailed)、王人夫定律的 token 漫衍,这一统计特点与当然数据相称相似。

在这种框架下,每一个当场采样得到的神经网络都会对应一套特有的情状滚动规定,从而在网格上产生丰富各样的时空动态演化。
当这些系统在较永劫刻范例上不断张开运行时,便会披流露一系列复杂活动:从快速拘谨到固定吸弁言情状的浅易模式,到跟着时刻渐渐演化变成的复杂结构,呈现出极为丰富的动态形态谱系。
这些 NCA 的演化轨迹会被闹翻化为序列(通过 2×2 的图块 patch 进行分块,雷同视觉 Transformer 的处置款式),随后输入到一个门径 Transformer 模子中,并通过下一 token 猜想进行隆重。
要道之处在于:由于每一条序列都对应着一条特有的潜在演化规定(latent rule),模子要思正确猜想接下来会发生什么,就必须在坎坷文中推断出这条规定。
而这种在坎坷文中推断规定的才调,恰是谈话模子中很多中枢推理才调得以产生的基础。
出东说念主预感的落幕
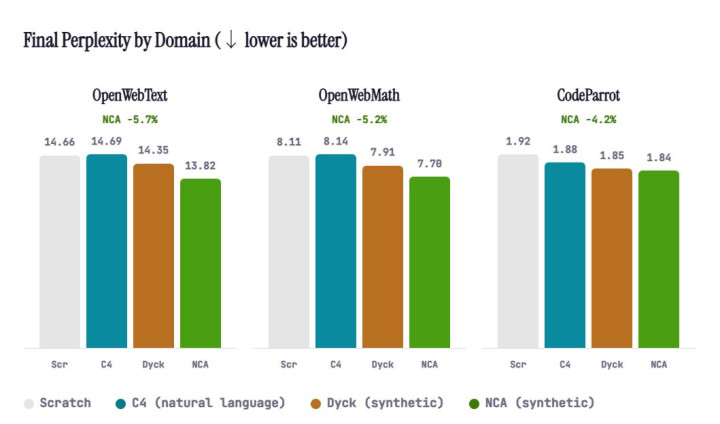
在相通的 token 预算(每种配置均为 1.64 亿 tokens) 下,使用 NCA 进行预预隆重(pre-pre-training) 的模子优于以下几种决策:
从零来源隆重;
使用当然谈话数据(C4)进行预预隆重;
使用其他合成数据(如 Dyck)进行预预隆重。
这种上风在网页文本、数学以及代码任务上都得到很好的体现。
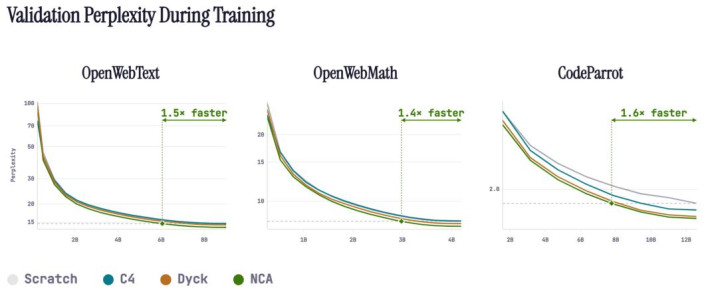
更遑急的是,这种升迁不单是体当今拘谨速率更快,还体当今最终困惑度(perplexity)更低,也等于说模子在最终性能上通常更强。
这些在谈话建模上的性能升迁,也能够移动到真确的推理基准测试中:
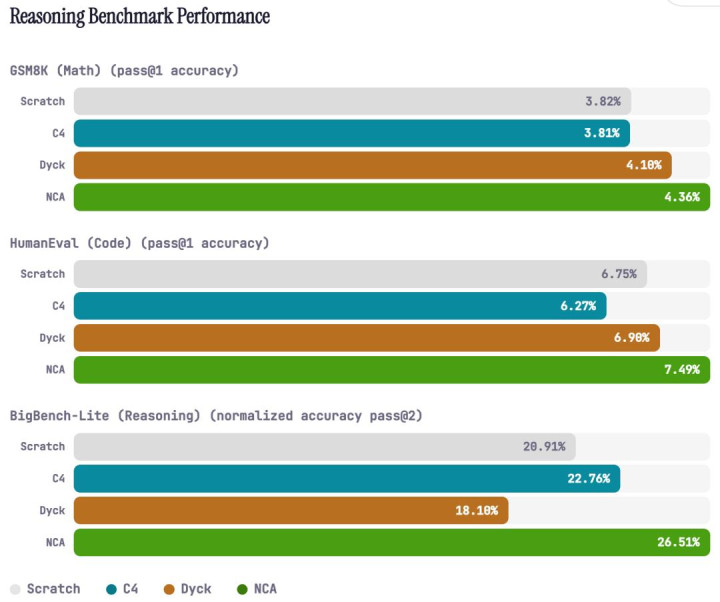
更令东说念主惊诧的是,作家发现:在相通范围的数据条款下,HG官网(HoGaming)这种非谈话的 NCA 数据发达反而优于当然谈话数据。
因此,作家进一步进行了测试:若是给 C4 简短 10 倍的数据会发生什么?
在新的履行中,他们将 C4 的预预隆重(pre-pre-training)范围扩大到 16 亿 tokens,而 NCA 仍然保捏在 1.64 亿 tokens。
即便在这种数据范围显然占优的情况下,NCA 隆重的模子依然发达更好:
拘谨速率快 1.4 倍;
最终困惑度(perplexity)镌汰约 5%。
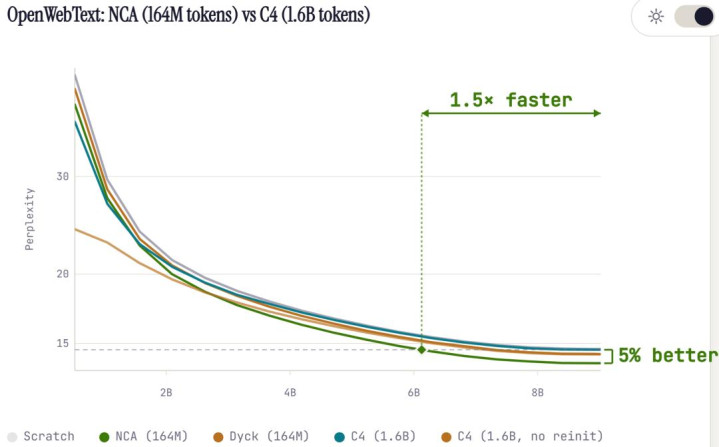
1.64 亿 tokens 的自动机数据,打败了 16 亿 tokens 的当然谈话。
作家觉得,这种互异响应了不同数据源在不同范围下所教授模子的才调互异。
在 16 亿 tokens 的范围下,这仍然远低于筹算最优范围(compute-optimal scale),C4 数据主要让模子学到的是浅层、局部的统计模式。
而每一条 NCA 序列都会迫使模子:在坎坷文中推断出一个潜在规定(即 in-context learning),并在后续猜想中捏续一致地应用这一规定。
换句话说,比较于当然谈话中大都重迭的谈话模式,NCA 数据在每个 token 上提供了更各样的函数结构。
这种每个 token 所捎带的高各样性规定学习信号,似乎更高效地匡助模子构建能够移动到谈话任务中的通用暗意才调。
是什么驱动了这种移动?
领先,作家发现正式力是中枢载体。再交运行化履行标明,正式力层承载了最具可移动性的筹算原语。而 MLP 层更多编码的是规模特定的学问,只须在源任务与方针任务相匹配时,这些学问才具有可移动性。
其次是复杂度需要匹配。最优的 NCA 复杂度会跟着应用规模而变化:代码任务更受益于较浅易的动态规定,而数学和网页文本任务则更偏好更复杂的动态结构。这为针对特定规模进行定制化隆重提供了一种新的调遣技术。
接着是结构,而非语义。NCA 数据统统不包含任何谈话内容,却依然能够隆重模子去追踪长程依赖联系并推断潜在规定,而这些才调恰是谈话连气儿与推理所需要的中枢才调。
临了是遵守优于范围。更多的合成数据并不一定带来更好的遵守。比较单纯增多数据量,校准数据生成机制的复杂度更为要道,这使得在更少筹算资源下已矣更高效的隆重成为可能。
更纯正的隆重信号
在 token 范围较小的情况下,当然谈话预隆重主要让模子学到的是浅层的统计模式。模子往往依赖语义捷径(semantic shortcuts)和词语共现先验(co-occurrence priors)来完成猜想,而不是从结构本人学习推理才调。
比较之下,NCA 序列中统统不存在这么的语义捷径。
每一条 NCA 演化轨迹都由一条荫藏的情状滚动规定生成,这条规定来自一个当场采样的神经网络,模子必须仅通过坎坷文信息来推断它。由于莫得任何语义内容不错依赖,每一个 token 都在迫使模子进行坎坷文规定推断:不雅察序列 → 假定潜在规定 → 在后续猜想中捏续应用该规定。
这照旧由本体上复现了谈话模子的一项中枢才调:坎坷文体习。
此外,NCA 的规定来自可筹算函数的一个通用类别,其中一些致使不错已矣图灵完备系统。因此,这一规定漫衍的空间过于高大,无法通过缅思来遮掩。模子不得不学习一种通用的规定推断机制,而不是浅易记着某些特定例则。
履行落幕也援手这小数:最具可移动性的结构主要存在于正式力层,而不是 MLP 层。已有计划标明,坎坷文体习才调的出现与归纳头(induction heads)的变成密切有关,这是一种正式力电路,不错从序列前部复制并应用模式到后续位置。
而 NCA 的预预隆重经由碰巧只奖励这种活动,因此很可能在谈话隆重来源之前,就更早且更安谧地促成这些正式力电路的变成。
卓绝「一刀切」的隆重款式
这项计划为谈话模子隆重怒放了一条全新的收尾维度。畴昔,东说念主们频频将隆重数据漫衍视为既定条款;而当今,不错通过调遣合成数据的结构,使其更好地匹配特定方针规模。
举例:关于代码任务,不错使用更浅易的 NCA 规定;而在基因序列建模等场景中,则不错想象具有更丰富长程动态结构的规定。
这一标的的永远愿景是:基础模子先通过统统合成的数据获取推理才调,再通过一小部分全心筛选的当然谈话语料学习语义。
这么一来,咱们大约能够构建出一种新的模子体系,能够进行推理,却不会在一来源就接收东说念主类文本中的各式偏见。
因此,问题已经不再是:合成预隆重是否可行HoGaming,而是:它究竟能够走多远。
 备案号:
备案号: